You tell your AI assistant you moved from Detroit to the suburbs. Three weeks later you ask it to recommend a coffee shop near you, and it suggests one back in Detroit.
It didn't forget you moved. It kept using the old fact instead of the new one.
This failure has a name. I call it supersession: answering with the current value of a fact that changed, and dropping the value that has been replaced. It turns out to be a stubborn, under-measured problem in AI agents. I built an open tool to study it, found that the obvious fixes don't work, and then trained a model to actually get better at it. Here is the short version.
The problem isn't reading, it's remembering
Modern AI assistants don't re-read your entire history every time you talk to them. Over months of conversation that would be impossibly expensive. Instead they keep a small summary, a memory, and update it as you go. The danger is in the update: when a fact changes, the assistant has to overwrite the old value in that summary. If it doesn't, the stale fact quietly sticks around and corrupts future answers.
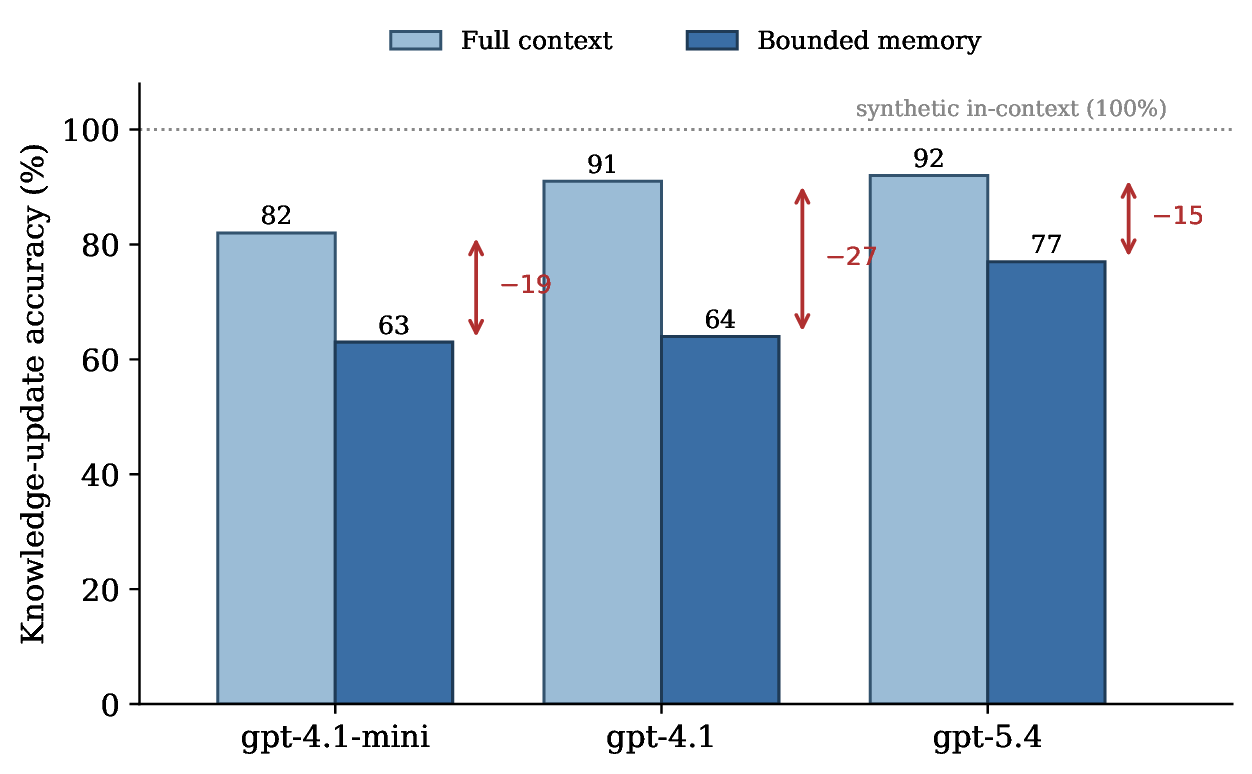
I measured exactly this on a real benchmark of conversations where facts change mid-stream. The result was clean. Take the strongest model available (gpt-5.4) and let it read the full transcript, and it answers these "what's the current value?" questions correctly 92% of the time. Force that same model to work from its own bounded memory instead of the full transcript, and accuracy falls to 77%. The model can read an update just fine. It fails at maintaining it. The gap is statistically significant, and it does not go away as models get smarter.
The two "obvious" fixes don't work
Naturally, you reach for the easy levers.
"Just use a bigger model." No. Stronger models read context better, so their full-context score climbs toward 92% and saturates there. But the memory-maintenance gap underneath persists. A better reader is not a better maintainer.
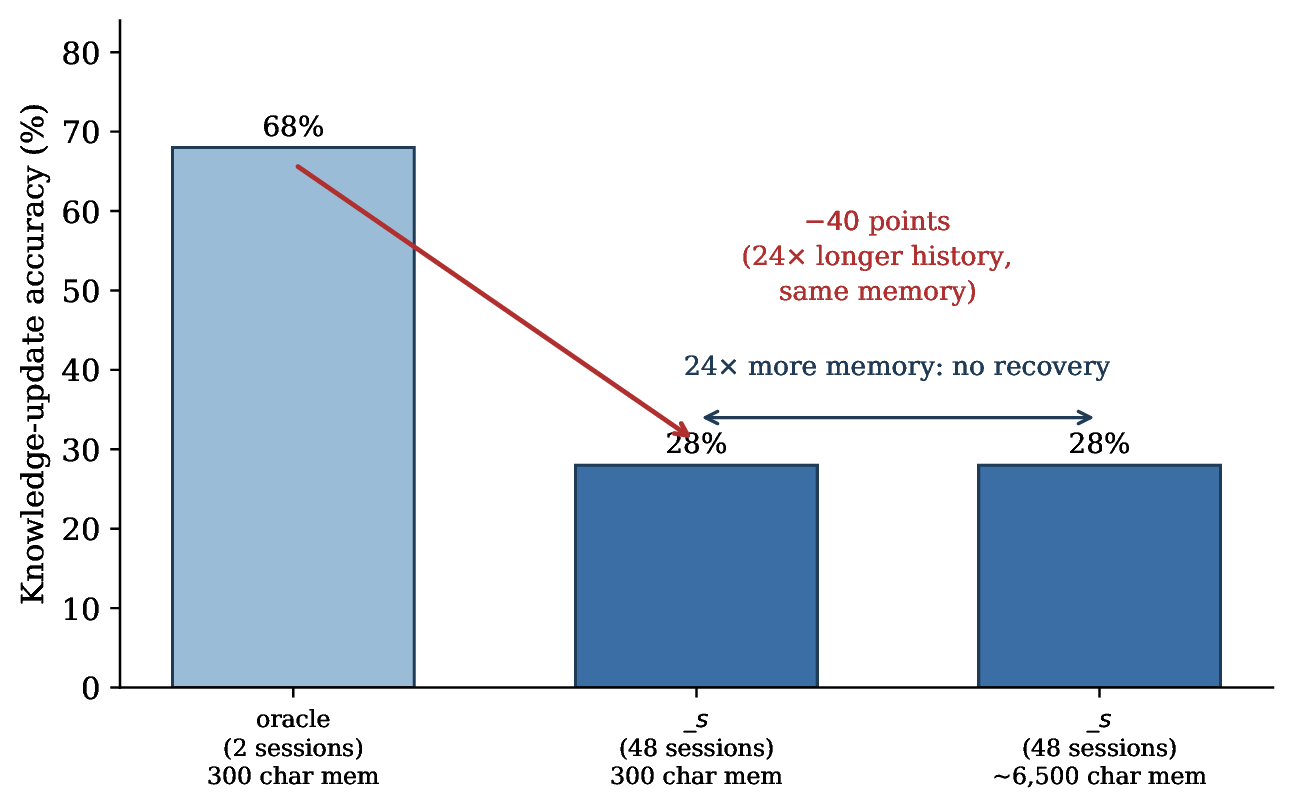
"Just give it a bigger memory." Also no. I grew the conversation 24 times longer, and accuracy fell from 68% to 28%. Then I gave the agent 24 times more memory to compensate, holding the compression ratio fixed. It recovered none of the loss: 28% to 28%. The failure tracks the length of the conversation, not how much memory you allot. You cannot buy your way out with a bigger notes field.
So: bigger brain, no. Bigger notebook, no. What's left?
The fix: treat it as a skill, and train it
If you can't fix supersession by scaling, maybe it is a behavior you have to teach. So I built Supersede, an open reinforcement-learning environment where an agent is rewarded for answering with the current value of a fact and gets nothing for citing a stale one. It plugs into the open verifiers / prime-rl stack the RL community already uses.
Then I trained a small open model (Qwen2.5-3B) on it with GRPO, a single run on one cloud GPU box.
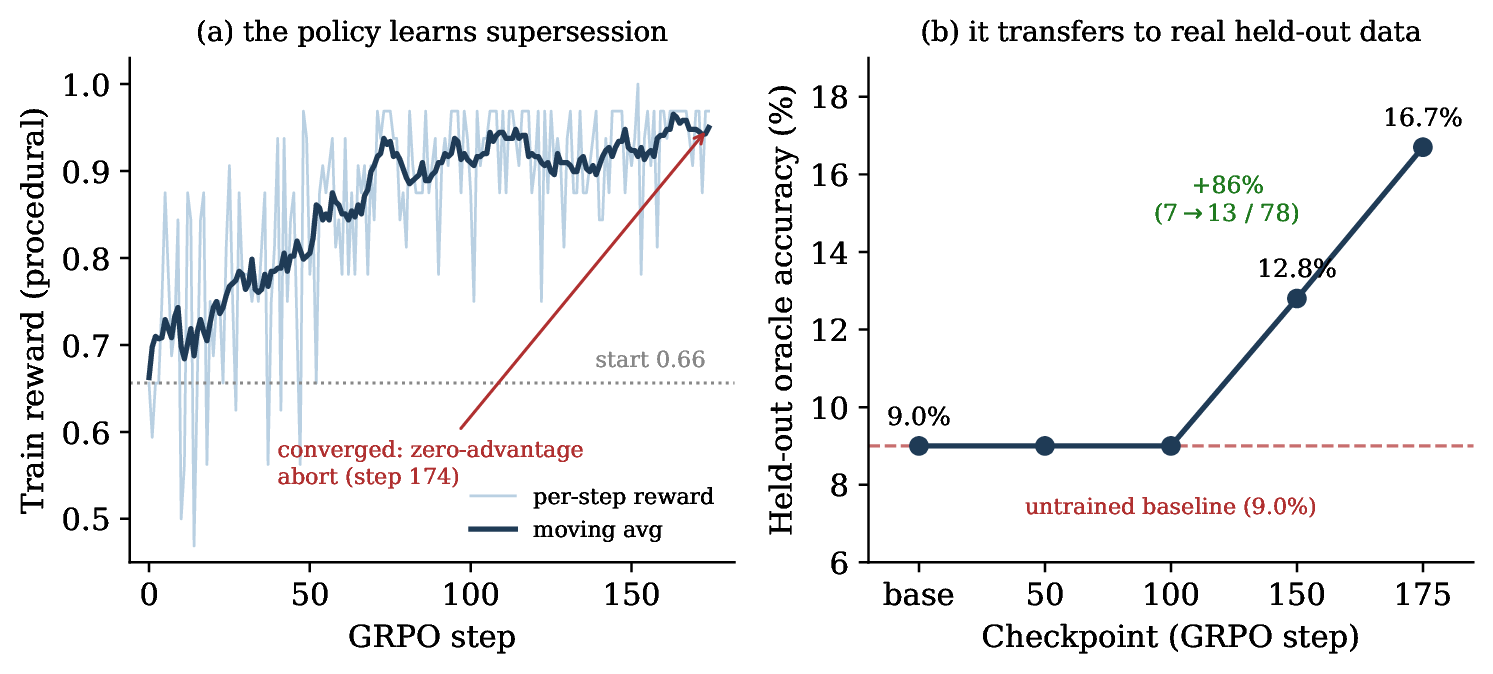
The result: on real, held-out conversations it had never seen in training, accuracy on these questions nearly doubled, from 9.0% to 16.7%. And it climbed in a steady, monotonic curve across training checkpoints, which tells me the learned policy carries the gain, not some quirk of the test harness. It was trained on synthetic practice and still improved on real conversations, meaning it learned an actual skill rather than memorizing an answer key.
The honest part
I want to be straight about what this is and isn't.
- It is a proof that the idea works, not a finished product. The model is small (3B), and 16.7% is still far from solved.
- Training effectively ran out of road: the model aced the synthetic practice (training reward saturated near the ceiling) and stopped having hard examples to learn from. The boxer didn't hit their limit; the gym did.
- The held-out accuracy curve was still rising when training stopped. That strongly suggests harder practice and a bigger model would push the number higher. But "suggests" isn't "proven," so I'm not claiming a bigger result until I show it.
Why this matters
Every company building a memory-equipped AI assistant, the kind that is supposed to know you, will hit this exact wall. An assistant that confidently uses your old job, old address, or old preferences isn't just wrong. It is the kind of wrong that erodes trust fast.
Today the field mostly measures this problem. Supersede is, as far as I know, the first open environment whose reward targets the temporal currency of a fact, and the first evidence that the gap can be trained down rather than only measured.
The diagnosis, the open environment, and the first gap-closing result are all out. If you work on agent memory, I would love for you to try it, break it, and push the number higher.
Built on LongMemEval, verifiers, and the Prime Intellect Environments Hub.
Paper: arXiv:2606.27472 · Code + environment: github.com/Vrin-cloud/supersede · Model + dataset: Hugging Face
